# SQL Performance Tuning
There are two goals Performance Tuning aims to achieve:
* to reduce the amount of time it takes a query to show results
* to reduce the amount of resources used to process the query
Note that a database is no different that a regular software we run on our computers and therefore is subjected to limitations of our hardware.
In order to run a query faster, we need to reduce the number of calculations we perform. To do that, we should know what affects the number of calculations and subsequently the querys' runtime.
Parameters that are in your control and affect the calculations are as follows:
* **Table Size:** Running queries on tables with hundreds (or thousands) of rows take shorter time than that of millions of rows.
* **Joins:** Our queries will likely to be slower, if we perform joins on two tables in a way that the resulting table has substantially increased row count.
* **Aggregations:** Aggregating multiple rows to derive a result demands more computational effort than merely fetching those individual rows.
Parameters that are not in your control and yet affect the calculations are as follows:
* **Queries by Other Users:** When multiple users are executing queries concurrently on a database, the database needs to handle a higher processing load, leading to slower overall performance. This becomes particularly problematic if some users are running resource-intensive queries that meet the criteria mentioned above.
* **Database Software:** Having a good understanding of the system you are working with allows you to optimize your queries within its limitations for improved efficiency.
For better perfomance:
* Reduce tables size: Perform exploratory data analysis on a subset of data. For instance, if we have a time series data, we can work with a smaller time window first. We can also `LIMIT` the row count to certain number during exploration phase. Once we complete the final version of our query, we can run it on the entire dataset.
Keep in mind that if you are performing aggregation, i.e. `COUNT(*)`, and use `LIMIT` to increase the speed, it wouldn't work. In order to speed our query up, we need to limit the dataset in a subquery before applying the `COUNT(*)` .
```sql
SELECT COUNT(*)
FROM
(
SELECT *
FROM employees
LIMIT 100
) AS tbl
```
is faster than
```sql
SELECT COUNT(*)
FROM employees
LIMIT 100
```
{% hint style="info" %}
Applying the `LIMIT` function as in the former query, i.e. in the subquery, is a very common approach for testing query logic. However, it will result in significant changes to your results. As a best practice, use it primarily for testing rather than obtaining actual results.
{% endhint %}
* Perform Simpler Joins: If we were to perform an aggregation after joining two table, we should try to do it before the JOIN occurs if possible.
Let’s check the runtime difference between the two following queries that count the number Walmart employees in the US for each department per region (hypothetically). Keep in mind that Walmart has over 1.5M associates in the US. This means that the first query needs to go through 1.5M rows to check matches. In the second query, this number drops down to hundreds (if not tens, i.e. number of departments) and the perform the JOIN, which means latter runs in a much faster manner.
```sql
SELECT
d.region,
e.dept_name,
COUNT(*) AS employee_counts
FROM walmart_employees_us e
JOIN walmart_departments d
ON e.dept_name = d.dept_name
GROUP BY 1,2
```
Instead aggreate before the JOIN:
```sql
SELECT
d.region,
t.*
FROM
(SELECT
dept_name,
COUNT(*) AS employee_counts
FROM walmart_employees_us
GROUP BY 1) AS t
JOIN walmart_departments d
ON t.dept_name = d.dept_name
```
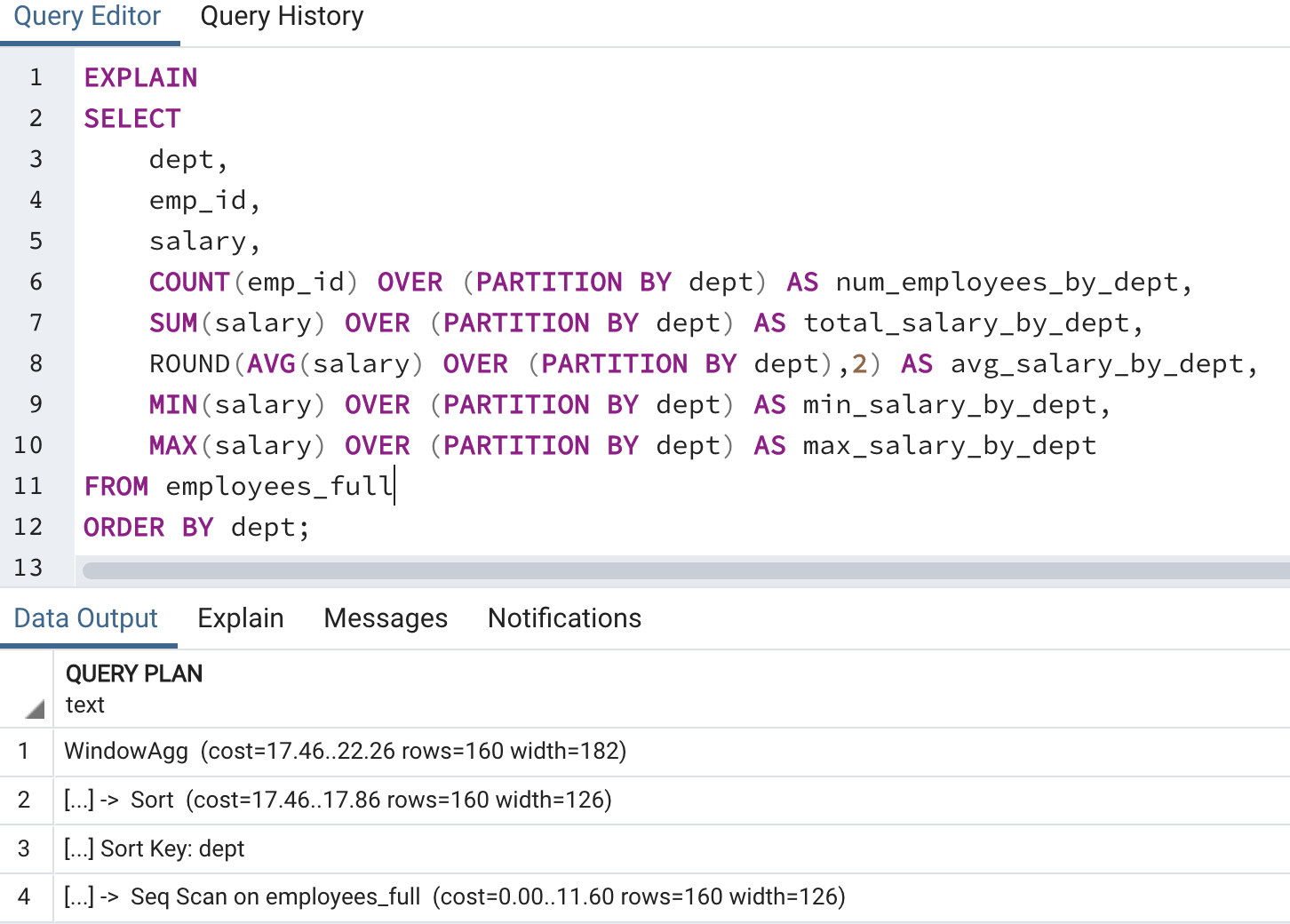
### EXPLAIN
The `EXPLAIN` command displays execution plan generated by the PostgreSQL planner for the given statement. We simply add the command in the begining of the query shown below:
The output is called the **Query Plan**, and though the results are not perfectly accurate, it's still a useful tool and shows the order, bottom to top, in which the query is being executed. The costs listed in the steps indicator of the runtimes and higher the number, the longer runtime.
We get the most benefit from the `EXPLAIN` when we run a query, pinpoint expensive steps, modify them and re-run `EXPLAIN` to if we have reduced the cost. Once again, `EXPLAIN` becomes especially helpful when run queries on large tables (with millions of rows or more), perform complex JOINs or Aggregations.
Check out [Postgres Documentation](http://www.postgresql.org/docs/9.0/static/sql-explain.html) for more details on `Explain`.